


The not so secret way to pay for faster AI inference

Look at this chart, this is a synthetic test running the prompt "say exactly 'Hello, world!'" 300 times for Claude Sonnet 3.5 v2:
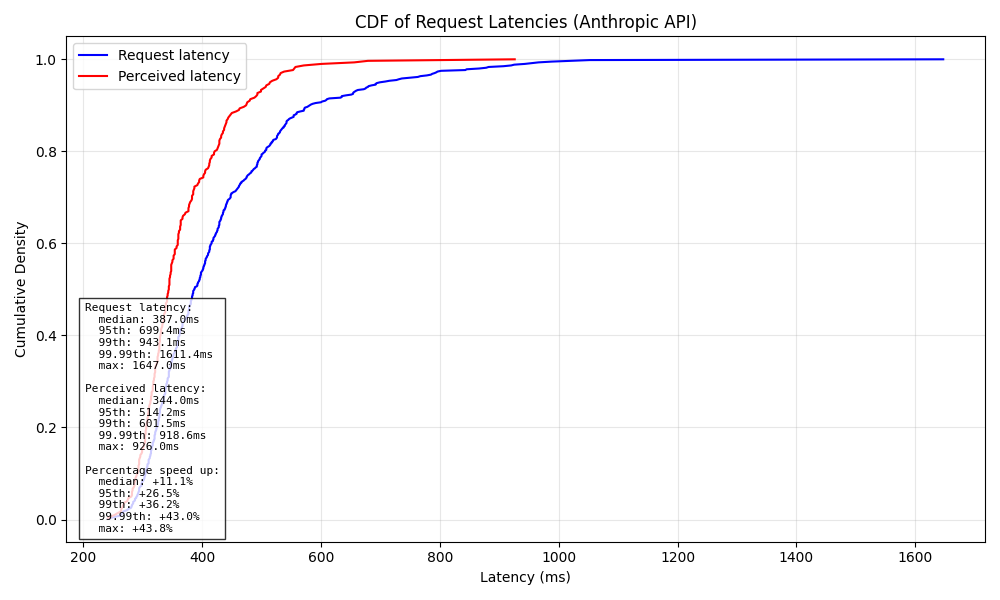
(Claude wrote all the analysis code, wow!)
In production, the speed up will at least double, as our contexts get upwards of 150k tokens.
Now wouldn’t you call this fake? Maybe magic, even?
The latency distribution is clearly worse than the perceived latency of LLM inference, so how in the world can the inference be faster than the request latency?
There’s no magic going on, this isn’t some token caching, no “pretending it’s an animation but it’s really a loading screen”. It’s not a secret API, we don’t have access to less loaded hardware, or a secret deal with them for secret faster models. We’re simply just paying 2x for faster requests.
Or, more specifically, we’re request hedging, and it’s used all the time in distributed systems. TLDR; instead of doing one request per inference, we do two, and we use which ever responds first!
The Perceived Latency graph is just the first responding request out of the two concurrent inference requests launched. This is really awesome when latency matters a lot in your systems, and you’re willing to put up the extra dollars to reduce it.
Note that this might not be the fastest completing inference, but it will be the fastest to give some form of progress.
But we use third party packages like Pipecat, and have many codebases, so I wasn’t going to add N-inference in multiple places. What I did instead was make a thin express proxy that pretends to be the Anthropic API, and runs any incoming request twice.
Then, when it pipes back which ever request sends the first byte the fastest.
https://github.com/danthegoodman1/AnthropicRequestHedging
It can probably be optimized a bit, I let Claude very loose on the codebase after giving it pseudo-code of what I wanted, then had to slap on a choke collar and coerce it into writing good code, and clearly Prettier decided it HAD to be at least 100 lines of code. So yeah blame the AI if it’s bad code ;) but it works!
And if you’re really chasing down those tail latencies and have more money to burn you can tune the HEDGE_FACTOR to increase the number of concurrently launched requests.
There are a few additional benefits of this method as well, and we can’t let those go uncaptured if we’re paying extra, obviously.
You can save the slow otherwise unutilized responses, and use it to compare deviation based on your prompt and settings. Really nice for seeing how consistently your agents perform in production! In theory you can also abandon streaming requests too, and you should be able to save some money there. But right now inference costs is not the limiting factor, it’s latency, so we’d like to see the comparison (internally I added a ABANDON_SLOW_REQUESTS option).
It also means you can get rid of timeouts (or make them long, like 3 minutes).
Cold shower for you: Timeouts are nearly always the wrong answer to solving latency.
I won’t dive into why now, but you don’t want to synthetically keep your system down just because a downstream dependency is taking 1ms longer to respond than your timeout, and you want to aim for what is called Constant Work: A system under duress should do the same amount of work as a healthy system, so the failure is simple, the behavior is predictable, and you don’t literally punish a struggling system with increased work.
From an end-user perspective, it’s much more frustrating to talk to an AI that’s not responding at all, than one that’s taking a bit longer to respond. It’s like slow moving traffic vs. gridlock, you know which one sucks a lot more.
Finally, this can easily be extended to add Vertex and Bedrock as additional providers, so you can run multiple providers for the same model inference request to hedge against provider-level downtime (*cough* OpenAI *cough*).
In a perfect world, we don’t have to spend twice as much for less than twice the improvement, and latencies are consistent across the board.
But, we live in the real world: A world of diverse network conditions, cosmic rays flipping bits, hardware failures (especially with GPUs), and LLM providers that may or may not be overallocating their GPUs.
You can even test how much request hedging would help your perceived latencies now: Just take some existing latencies, and construct a CDF (see chart.py), then, construct a second line by putting all your latencies in groups of two, then for each group pick the fastest one and plot it.
Ask any distributed systems engineer you may know, they’ll love to fill your ears for hours about how the vast majority of their code is handling the real world’s problems, and how little is for the perfect world.