🤓 TL;DR: FireScroll is a config database designed to be deployed in high node counts in every region you operate in. It materializes a linearizable (per-partition) log to disks locally in each region so that lookups are sub-ms from your services.
It’s perfect for use cases like a DNS provider, web host, feature flagging, A/B testing, and more as it’s optimized for high read concurrency.
What kind of database do you use if you need to serve records at extremely low latency, anywhere in the world at the most absurd scales?
Say you are a DNS provider serving DNS records, a webhost looking up routing configuration, fetching user feature flags, or a SSL termination gateway… what database do you use?
I got magnificently “nerd sniped” by this question:
While I happen to be a chronic nerd snipe victim, it sometimes results in some pretty cool stuff like FireScroll.
Why “FireScroll”? Well it’s a database based around a distributed WAL that feeds materializing nodes to snapshot the WAL into KV.
Scroll → Log
Fire → Performance
Get it?… Also I have firescroll.comsomehow so it was too perfect.
In fact, this was a nerd snipe from another nerd snipe I was already working on, where I wanted to serve sub-ms configurations in 26 regions around the world. I guess I can finally get back to that (don’t worry that has a super slick name too).
FireScroll is designed to serve extremely high read throughput while also being as highly available as possible. You can kill nodes, scale it up to thousands of cores, take entire regions offline, and it keeps serving sub-ms reads of datasets enormous in size.
It tackles a very specific use-case, and is meant to be used in addition to a traditional OLTP DB like CockroachDB or Scylla.
Requirements, and what’s not required
The list of requirements is pretty small:
Extremely low latency reads at fan-out scale
Backup and restore of granular partitions
Ability to spread out data among many disks to allow for massive data set sizes (PB range)
It’s so small, it might be better to mention the things that we dont need instead:
Consistency (we can be eventually consistent)
Read-after-write guarantees
A complex query language (SQL)
Long-running TCP sockets
Repartitioning
A few more nice to haves:
Atomic operations
Comparability (do X only if Y)
HTTP (for runtime-limited environments like Cloudflare workers)
Why not use Cassandra or Scylla?
I’d love to use Scylla, but there are 2 major issues.
The first issue is that the Cassandra model is so eventually consistent that it can break pretty badly, so badly it ends up being considered normal behavior.
This is fixed in the immediate term by reading from multiple nodes and comparing results (CL=TWO,QUORUM,LOCAL_QUORUM), since we are assuming not every node is in a permanently inconsistent state (although they can be).
To me that seems like a bandage, not a fix.
This permanent inconsistency is remedied in the long term with “repairs”, which leads to the second issue: Scylla Manager.
The free version only supports up to 5 nodes, which is a problem if I want to serve KV from all 26 fly.io regions. You can run repairs manually, but this process is tedious, must be done one node at a time, and prevents you from modifying nodes during this process.
Most providers don’t privately network all their regions together, and some don’t even have that capability. This means you either need to publicly expose all nodes, or privately network all VPCs together, then tell each node about each region… It’s a bit of an operational hassle to get multi-region.
I still love Scylla FWIW, but remember I’m getting massively nerd sniped here.
Aren’t you crazy for making your own DB?
Not at all.
First, I didn’t really create “a new DB” like CockroachDB or Postgres, I just intelligently(?) glued together multiple really great existing technologies and added some more functionality on top.
That also just described everything ever programmed, but you get the point.
More importantly, and more often than not, building a bespoke datastore for a specific use case has the benefits of:
Increased performance (sometimes many orders of magnitude)
Reduced complexity (keeps the codebase really small, and thus far less room for errors)
Easier to run
Architecture
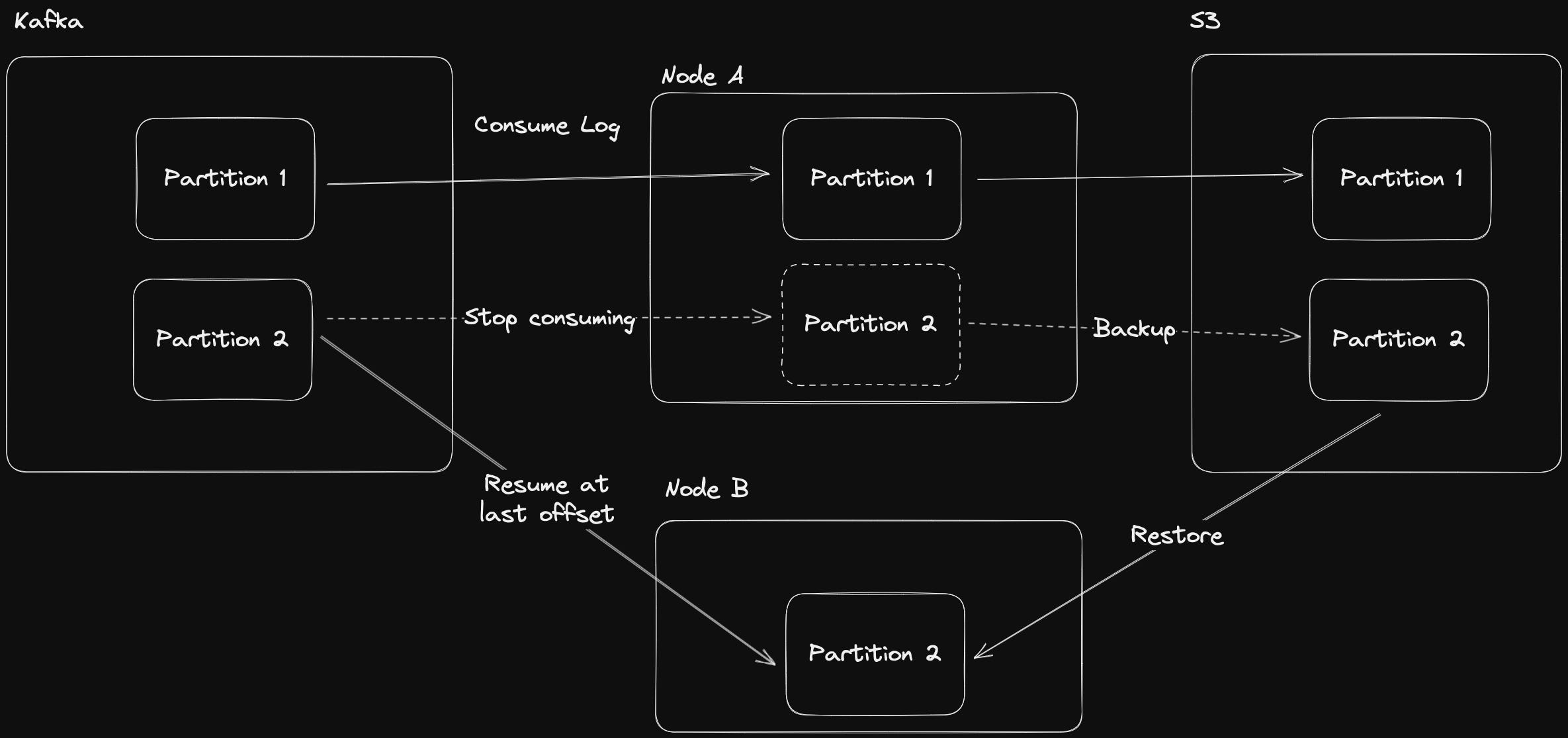
TL;DR it’s Kafka connected to Badger where each partition of a topic is a distinct Badger DB that backups to S3 and can be moved around different nodes.
Specifically, I looked at existing databases and turned them inside-out!
Rather than having multiple nodes with each their own WAL, I used a single shared distributed WAL which nodes consume from, materializing (truncating) to disk and backing up that snapshot of to S3 so that they can be restored on other nodes (rebalance and replication events) without needing to consume the entire WAL history. This is specifically important for allowing us to have a really short retention period on the WAL!
Components and Terminology
Namespace
A logical namespace of data, contains all the nodes and the Kafka topic that is used for mutations. Each node can belong to a single namespace.
Node
FireScroll internal services diagram
An instance of FireScroll, contains 1 or more partitions and consumes from Kafka. Nodes run many micro services internally such as the API server, the internal server, the log consumer, the partition manager, the partitions themselves, and the gossip manager.
Nodes use Gossip to communicate within the same region to enable transparent get request proxying to remote partitions.
Proxy remote read diagram
Replica Group
Diagram of nodes across replica groups within a region communicating over gossip
A node maps to a single replica group. A replica group is just a Kafka consumer group. And within a consumer group, Kafka maps partitions out to a single consumer in the group. By having more of these in a local region, you get replicas of the data. That increases availability and throughput at the same time, since any replica of a partition can serve a read.
No need for N/2 + 1, you can have as many replicas as you want, since other than proxying get requests for remote partitions they don’t have anything to do with each other. Any node can serve any mutation to Kafka.
Partition
Kafka to DB partition mapping diagram
The smallest unit within FireScroll. A single mapping between a Kafka topic partition and a Badger DB. These can move from node to node. All data is stored and backed up at a partition-level.
Partition Key
Partition key and sorting key partition mapping diagram
This is the key that is used to determine what partition the record is placed in. For example maybe this would be a domain name, or a user ID.
Sorting Key
A secondary component of the primary key, this key determines how the record is sorted within the partition.
Keys use the same semantics as DynamoDB or Cassandra/Scylla
The WAL or Log
The distributed WAL that Nodes write to in order to quickly make mutations durable (put, delete). Uses Kafka or Redpanda (prefer Redpanda!).
The beauty of this system is that we can get mutation durable super fast, while letting the downstream nodes read at their own pace. This means that local nodes can get updates in ~15ms, while nodes on the other side of the world update in ~350ms, all without any additional strain on the system since no write coordinators are worried about timeouts and retries.
Kafka also manages the balancing of partitions among nodes for us! And since each partition is linearizable, it guarantees that all mutations to a partition are in the order it was submitted.
While on the topic, I just wanted to shout out **Alexander Gallego** and the team at Redpanda. Their activity in the Redpanda community Slack is the most impressive I’ve ever seen. Support is the number one thing I look for in an infrastructure company, and I can’t recommend these guys enough. Many engineers were happy to jump into discussion on my questions, and guide me through Golang-Kafka semantics. Specifically thanks to Travis Campbell and Travis Bischel for tolerating a Redpanda noob!
Region
Diagram of multiple regions consuming from Kafka
A logical region where multiple nodes are hosted. This could be a cloud AZ or full region depending on your semantics. But we want lots of these all over!
While FireScroll is not particularly aware of a region, it’s important that a region has its own set of replica groups.
Backups and Restoring
Backup and Restore lifecycle diagram
Nodes can optionally be marked to create and consume from backups. You specify an S3 bucket, whether you want to create backups, and whether you want to restore from backups.
This gives lots flexibility like:
All regions have a single replica group backup to a regional S3 bucket for redundancy and low-latency restores
A single replica group in a single region does backups, and all other regions read from that, trading redundancy and speed for reduced storage costs and resource requirements
When nodes restore a backup, they resume consuming from the last mutation included in the backup. Similar to how a traditional DB will join the snapshot and the WAL to answer a query, FireScroll will use the snapshot + the Kafka WAL to catch up to the current state quickly.
The Partition Lifecycle
Each partition starts off mapped to a node by Kafka via consumer groups. The Kafka partition feeds the partition DB on the local node until a rebalance occurs. When a partition is removed from a node, the node deletes all local knowledge of it, as it is able to restore that from S3 later.
When a rebalance occurs, a partition is mapped to another node. First, it will check for a backup in S3 if it exists. If so, then it will restore that to disk and check the latest mutation offset. It will then attach to Kafka at that offset + 1 and consume to catch up.
If it does not exist, then it will start consuming from the log. This is only the case on first boot.
If a node restarts, then it will first check the local disk to see if it has the partition. If so, then it will see if that’s more up to date than a remote S3 backup, using which ever is farther ahead (this can be optimized based on DB size too, so it does less work based on whether reading more log or restoring from the backup is more efficient, but this is not yet implemented).
This simple lifecycle means that partitions can be killed and rebalanced aggressively without much consequence. Add replica groups on top and you’re never dropping a read. Partition topologies are communicated instantly across gossip (before the node even goes fully offline), so all nodes are aware of a dropped partition and can immediately shift writes to another replica.
More partitions = smaller partitions, which makes backup and restore faster.
The read path
When a read (or list) request comes in, FireScroll hashes the primary key in the same way Kafka does to find the partition. If the node holds that partition, it serves it instantly. If it’s remote, then it will proxy the read for you.
You can also read multiple keys at the same time, and each partition involved will serve a stable snapshot.
The write path
Puts and deletes are considered a “mutation”. When a node receives an mutation request, it bundles those mutations up by partition. It then “produces” then to Kafka so that each down stream partition will get that partition’s mutations only.
There is an optional if statement that can be provided per-record for put and delete operations, powered by the expr package. If this evaluates to false, then the put or delete will not happen. This greatly reduces the consequence of no read-after-write, as you can tell mutations only to apply if the record is still as you last read it, or if it still has some property value!
Each consumer pulls that partition’s mutations at their own pace, so network partitions and high latency only affects the nodes reading, not the writers, and more importantly not the write coordinator node.
Badger
Badger is fast. Really fast.
I had originally used SQLite, but Badger blows that out of the water by at least 50x for throughput and 10x for latency. We don’t need everything SQLite has to offer, we just need KV speed and transactions, and that’s what Badger excels in.
Plus I can hook into the backup lifecycle right in Golang without esoteric knowledge of how the SQLite WAL works!
Why is this different?
I’ve already mentioned how this is basically inverting the traditional distributed DB architecture, but I wanted to highlight why this makes way more sense:
FireScroll is a single large WAL with lots of tiny dbs.
Traditional distributed DBs like CockroachDB or Cassandra are lots of little DBs with lots of little WALs.
Multiple WALs means that you either have to sacrifice significant performance for consistency (CockroachDB), or risk nodes being out of sync, sometimes permanently until repair (Cassandra). It also means that write coordinators have to baby-sit the entire write lifecycle of all nodes involved, causing either performance or consistency issues. When you’re talking about the scale of hundreds of replicas, this is not a good solution.
By sharing the same WAL, there’s no chance they get in a state of being permanently de-synced, and you don’t lose any performance for read throughput. Nodes are not responsible for keeping data persisted until remote replicas acknowledge a write to disk. Something that is complex and already handled by Kafka.
If you think about what the WAL is used for as well, it’s used for quick durability. Why would I make every node pay the WAL fee when I can make one cluster handle the WAL, and all the nodes can be pure read performance?
<aside> ☝ There is a WAL in Badger, but it’s probably 1/100th of the compute cost of a traditional DB, and FireScroll garbage collects it so aggressively that it’s basically not even there.
</aside>
In the situation of Cloudflare, Vercel, LaunchDarkly, or any other provider where read-after-write is not needed, optimizing for the 100,000,000:1 read to write ratio benefits from this infrastructure.
It also doesn’t result in multiple cascading replicas like Cloudflare’s Quicksilver does:
Rather FireScroll has a very flat hierarchy, which makes it easier to manage at small and large scales:
Diagram of FireScroll’s flat replication hierarchy
Performance
Absolutely filthy.
FireScroll only adds a few locks (most are RW locks so reads are concurrent) over Badger. Latencies are measured in microseconds, even if a remote-lookup is needed.
While it may seem counter intuitive, higher partition density often results in higher performance. This is because there is less likely to be a network hop for a read. So optimizing for scaling nodes up and creating replicas before spreading out partitions is more advantageous. Scale vertically and create replicas until storage becomes a concern, then spread partitions out to reduce the storage requirements per node.
Write latency is impressive too. The nodes are so performant they can easily read from the log as fast as you can produce to it. End-to-end latency ranges from 15ms to 350ms depending on how far away the node is from the Kafka cluster.
I’d love to bench FireScroll against Cloudflare’s Quicksilver, but I’ll probably never be able to test it at that scale nor have the opportunity to get metrics for Quicksilver. Quicksilver is the only other purpose-built datastore I know of to tackle this use case.
I’m looking forward to running this in all 26 fly.io regions for another project!
Downsides
This is not a perfect system, here are a few of my least favorite things:
No repartitioning
There’s not much penalty to starting with hundreds of shards, so consider the max scale you want up front!
There’s no remapping of records now, so a partition count change would very much break things badly.
You can recover by manually resetting offsets, and the nodes are aware of the partition count so they will refuse to start if there is a partition count mismatch.
Kafka/Redpanda
Didn’t I just spend this whole time talking about how smart it was to use this, and how great it is?
Yes, but it’d be nice to not need it. Think of it like needing Zookeeper for Clickhouse, or etcd for Kubernetes. It’d be nice to not have to deal with the extra infrastructure, but it’d also be 10x more work to build that in!
Badger can be big
With performance comes a more disk usage than something like SQLite, bbolt, LMDB, Pebble, or even RocksDB.
Future work
Atomic batches and If statements
By submitting multiple put and delete operations at the same time, you can have them commit within the same partition atomically.
Combined with If statements powered by the awesome expr I can build a mini SQL.
Update only if the _updated_at timestamp is still what you last saw? Delete only if data.domain.cert_fingerprint == xxxx?
Sounds great to me!
Incremental Backups
While this isn’t such a big deal with S3 retention policies, only backing up the changes since the last backup would be a LOT faster.
Repartitioning
Maybe I’ll tackle this one day! But this will be… complex… I’ll have to elect a leader (probably the same that’s elected for backups) to rewrite the current state to another topic, and thus repartition the data. Then the nodes can restart consuming from the new topic.
In theory one could be done on disk as well where they repartition without rewriting to the log, but making sure that resumes across node restarts is tricky.
The current solution is to just re-write the entire DB to a new namespace :P
Advanced Metrics and Tracing
Metrics on partition activity, density, size, request latencies, end-to-end mutation latencies, and more.
This will be relatively easy to add, but is less important than adding some of the other features mentioned above!
Change Data Capture/Changefeeds
Because mutations are powered by Kafka, you get CDC built in! If they have conditionals that don’t apply that’s something to consider, but it’s also easy enough to feed changes right back into Kafka for a true CDC!
Closing thoughts
I’m really happy to have made a database that I think can effectively serve sub-ms reads across an arbitrary number of regions at an arbitrary scale, that’s actually easy to manage!
In tackling such a very specific use case directly, it can do so better than any generalized solution out there (or at least, that I could find)!
Whether or not I am the only one that ever uses this, I learned so much more about distributed systems, Redpanda, Badger, and further honed my gossip knowledge and experience.
I feel really comfortable with each of the individual parts now, easily enough to use in production at varying scales. Combined, I think they are really amazing together!
Also, here is that full cover image, made with some clever Midjourney prompting:
Beautiful flaming scroll icon for a database for low-latency key-value reads served globally. Concept fire, flames, papyrus, paper, scroll, quill and ink, database, data. Flat render, subtle gradients, no letters.